

Dismantling the illusion of AI chatbots: introduction
An introduction to a three-part series of essays demystifying AI products: (1) The generative AI, (2) the user interface, and (3) the fictitious chatbot character
Oh, this is good! Microsoft Copilot is happy to churn out a pleasant, funny, and stylistically sophisticated message to address what I am asking it. Never mind the overdone metaphors, this reply is personalized, unique, and even uses “I” to make me feel like someone hears me and I’m not alone. And it ends with an appealing invitation to continue the conversation.
On his excellent Substack about artificial intelligence, Cognitive Resonance, Benjamin Riley recently published a conversation with data scientist Colin Fraser. That conversation immediately caught my attention and inspired me to find out what else Fraser had published. His work on Medium is fantastic—smart, accessible, and deeply critical of AI hype. After reading his essay, “Who Are We Talking to When We Talk to These Bots,” which he published in February 2023, just four months after the release of ChatGPT, I had a conceptual breakthrough. Fraser’s approach in that essay led me to adopt and develop the three-part approach I’m publishing here.
As Fraser explains, these three components of an AI chatbot program create user experiences that feel smooth and intuitive, effectively making us forget that we are interacting with a computer. Of course, that's intended by AI developers and brand marketers, but it's crucial that we not forget that AI chatbots are make-believe conversationalists pretending to know and hear us. Real emotional valence and attachments are being created and curated, which can easily obscure the larger social and ethical issues at play when we use these technologies.
This series of essays is about the illusion of AI chatbots: Who is on the other side of this conversation? What is this chatbot persona that is ready to write back at any time of day? How is this powerful illusion created, and why should we care?
The premise of this approach is that it's worth asking who and what EXACTLY we are talking to when we use one of these programs, because this deeper understanding will afford us the expertise to know whether to use an AI chatbot for a particular task and how to do so responsibly. My approach here presupposes that it’s important to examine the technology itself1, feeling out its affordances and limitations.
When Fraser wrote his essay, he was referring only to the early version of ChatGPT. Much has changed since February 2023; we are inundated with easily accessible AI chatbot products on every device, and these programs have undergone much additional development and refinement. In this post and the three subsequent ones, I retain Fraser’s structure of breaking down the three elements of AI chatbot design, but I have adapted his approach to encompass many different programs and to highlight a hands-on, experiential approach to each aspect.
I recall the first time I heard about ChatGPT, which was in November 2022. I immediately felt that this new (to me) technology would hit education, and especially writing teachers, hard. It was clear from the beginning that students would be one of the primary audiences for these programs. I’ve been trying to understand what was happening, mainly because I teach writing at the college level and coordinate the writing program at my large, public university in Utah, where we employ around 70 adjunct instructors in the English department. I had to know enough to help these hard-working teachers understand the new predicament.
This project aims to dismantle the illusion of AI chatbots and is primarily intended for other teachers and faculty like me. We can think through the pedagogical implications of this technology much more productively if we understand how the technology works and how the chatbot design operates.
AI chatbots in three parts
An effective way to understand AI chatbot products is to think of them as containing three interconnected components (which I explore in separate essays in this series):
The generative AI technology (language models)
The specific user interfaces of AI chatbots
The fictitious chatbot character that completes the illusion of interacting with an intelligent entity
These three aspects, when assembled into a pleasant, easy-to-use, and frictionless user experience, all but guarantee the exuberant and largely uncritical adoption we have seen since OpenAI released its first commercial language model. And more than that, these three elements have been expertly designed by big tech companies, with grotesquely bloated budgets and resource requirements, to bamboozle the public (and us, and our students) into believing that AI adoption is inevitable.
How do language models work?
The next post, which is Part 1 of the three-part structure of AI chatbots, provides a hands-on analysis and demonstration of how generative AI works; for now, and as part of this introduction, I’ll cover the general structure of language models.2
The first element of any AI chatbot is its underlying software—the computer program that works to "understand" a user's prompt and produce new text. How do computers process human language and complete our inquiries in more or less satisfactory ways? What sorts of computer programs are capable of such language tasks?
The name of OpenAI's program, "ChatGPT," provides a good starting point.
G stands for Generative
P stands for Pre-trained
T stands for Transformer
A GPT system is a language model, specifically a "generative language model." Although only OpenAI uses the "GPT" designation in its program name, all other AI chatbot programs are also GPTs. These language models are the result of years-long, multimillion-dollar investments and human effort that have been largely funded by the world's largest technology corporations (mainly in the United States, but also in China). Without this financial and human capital, the current proliferation of language models would not have been possible.
Let's break down the GPT process, remembering that these three elements are deeply interconnected:
G: Generative
The basic computational architecture of GPTs is the classic command/execute computer structure. The "command" is the string of words a user inputs to the language model, and its basic code instructs it to "execute," which means that language models complete the word string from the user's prompt by adding more words to it. In this way, a model "generates" new text--it completes the prompt we give it by predicting the next word in a word sequence. In other words, a GPT is a sophisticated text completion engine that produces unique text on demand.
P: Pre-trained
In order to predict what the next word might be in a word string, a language model is "pre-trained" on a massive amount of undisclosed human text. Rather than human programmers giving computers explicit, step-by-step manual instructions, such as grammar rules and vocabulary lists, a contemporary GPT system uses a so-called "neural network" (a mathematical structure inspired by how brain neurons connect) to automatize the identification of complex linguistic patterns in huge amounts of sample text that tech companies have scraped from the Internet over many years. Thus, a GPT model computes language patterns from a huge training corpus on its own, in a time-consuming process that is repeated billions of times across vast amounts of text, powered by fast parallel processing GPU chips--and that requires massive amounts of energy. Its predictive operations stem from this pre-training of word relationships.
T: Transformer
A transformer is a novel type of neural network that comprises various specialized layers or components, forming the core of GPT systems. It defines how data flows through the system, how "attention" mechanisms work, which mathematical operations happen at each step, and the specific arrangement of neural network components. A transformer takes a next-word prediction approach in an empirical process. A few key aspects of this transformer architecture are summarized below:
Pre-training is the process that teaches this transformer architecture how to "understand" language. This is done by "breaking down" words into something the computer can recognize and compute: numbers.
Transformers treat words, not entire sentences or passages, as the basic unit of analysis. First, they represent words as "tokens" (smaller units of meaning), which are then expressed as long lists of numbers; these numbers are called "word vectors" or "word embeddings."

Example of tokenization using OpenAI’s Tokenizer
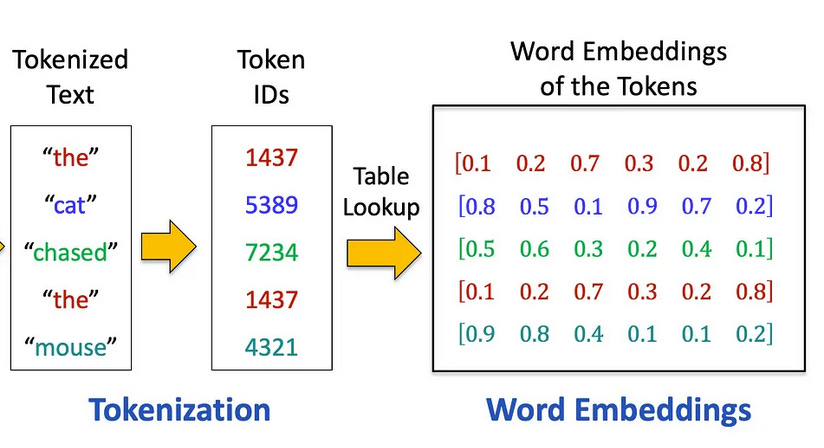
Each token is assigned a numerical ID, converting text into a sequence of numbers
The transformer takes each word vector and represents it spatially in an imaginary "word space," where words with similar meanings are placed closer together. In this way, word vectors (strings of numbers) enable mathematical and statistical operations that categorize and measure syntactic and semantic word similarities.
Language models compute and encode vector spaces with hundreds or even thousands of dimensions, a computational feat pioneered by Google in 2013 as part of its machine translation efforts and access to larger datasets. Google engineers also developed the full transformer architecture using massive training data and new, high-performance GPUs in 2017.
Transformers are organized into dozens of layers, which take sequences of vectors as input to calculate word relationships and predictions through an "attention" process. This process determines the relevant context and attempts to predict the next word according to relevance by matching linguistic patterns from the training data. In this chain of operations, designers can adjust weight relevance parameters.
New (or updated) models, which large tech companies release regularly, are more complex and larger than previous models, resulting in increased vector dimensions and transformer layers. Fundamentally, researchers do not fully understand exactly how language models keep track of all this information. This entire process of word generation requires hundreds of billions of mathematical operations and involves repeating the process billions of times, once for each word in the training data. This is computational labor at scale--again, made possible by large investments of financial and human capital.
Before a model is released to the public, it also requires Reinforcement Learning with Human Feedback (RLHF), for which tech companies utilize human workers to fine-tune the GPT output. Left alone, language models mimic the text data from the Internet without screening it for toxic content, misinformation, biased viewpoints, and low-quality text. In other words, there is an alignment problem: the model's goal to predict the next token and continue the input text can conflict with human goals to access helpful, truthful, conversational, and safe text. Thus, human trainers provide feedback on the generated outputs to align them with the desired goals, using a ranking system of numerical rewards and penalties that the model then considers as part of its token prediction process. This process is time-consuming, expensive, and exploitative of vulnerable human labor (often in the Global South or through platforms like Amazon's Mechanical Turk).
So when you interact with GPT, you're seeing the results of machine learning applied to language. This system learned to analyze and generate human-like text by studying patterns in billions of examples, rather than following pre-written rules. GPTs are “stochastic parrots,” capable of generating unique sequences of words that adhere to the linguistic patterns they have learned.
What are the takeaways?
It helps to know this technical, empirical background to better grasp why language models "hallucinate" and generate text that we identify as a "mistake." Strictly speaking, such "mistakes" are part of the guessing game language models use to predict each new word in a sequence. It would be more accurate to use the term “AI mirage.”
Language models do not have access to the real world or reality. Their text production is a mathematical operation that uses a binary number system to generate “decontextualized meaning.”3 Because language is ambiguous and context-bound, humans think about the real context when they use language. Language models do not use such faculties because real context cannot be computed as deterministic rules (well, not yet).
The more precise linguistic context a user provides in their prompt, the more "accurate" the model's output will be, as it has more to work with in terms of excluding word vector spaces from unrelated contexts.
Similarly, the more texts are available in the training data about a particular topic, the stronger the linguistic patterns are, and the more reliable and accurate the generated text becomes. For less common questions or topics, the plausible-sounding output shows a higher potential to be inaccurate, while it reproduces the form found in the training data.
Language models cannot cite which texts they have learned from specifically; so in a way, the generated text can be seen as a form of paraphrase or "papier-mâché"4 rearranged from all the human-authored source texts used in a model's pre-training. This factoid has direct and specific consequences for academic writing, which operates in a system of attribution, intertextuality, and citation.
GPTs have been almost exclusively developed to be packaged into chatbot consumer applications by big tech companies that wanted to monetize their returns on investment.
The point is that so much is at stake here. From a business perspective, big tech stands to lose (tons of) money, prestige, and influence if their AI calculations do not succeed. They’re protecting their interests with aggressive marketing and the most carefully developed interface and chatbot designs. All of us in education feel the impact of AI chatbot deployment acutely and persistently every day and in every class we teach. I don’t think it’s an exaggeration to say that AI has engendered a crisis for education. As users of this technology, we are exposed to a myriad of ethical and social issues that are far from settled. Aspects of this AI chatbot deployment are downright dangerous and morally corrupt. Dismantling the illusion of these chatbots is one small step in resisting the hype.
Stay tuned for the next essay in this series: a hands-on exploration of how language models generate their word/token completion predictions. Seeing a raw language model at work is quite fascinating.
Colin Fraser will probably never come across my writing here. But if he does, I want him to know how influential his essays have been for me. I hope to inspire others to read his work as well.
Notes:
Rita Raley and Jennifer Rhee explain, “For critical AI studies as it exists now. . . the problematic is how to think from within the actual techniques, tools, and technologies of ML [machine learning] and how to leverage that practical knowledge in the development of new critical frameworks and methods, as well as countermythologies and epistemologies that might help enact a different way of living with AI” (p. 188).
I take this phrase from Chapter 1 in this edited collection. The entire book is a tour de force of “AI” demystification, providing a historical and critical-technical analysis of machine learning and its cultural and social impacts.
The metaphor comes from Bender and Hanna’s new book: “With LLMs, the situation is even worse than garbage in/garbage out—they will make papier-mâché out of their training data, mushing it up and remixing it into new forms that don’t preserve the communicative intent of the original data. Papier-mâché made out of good data is still papier-mâché” (p. 113).