

The semantic illusion under the hood of LLMs
Part 1 of a three-part series of essays dismantling the illusion of AI chatbots: (1) The generative AI, (2) the user interface, and (3) the fictitious chatbot character

This is the second of four essays in a series dismantling the illusion of AI chatbots. The first essay was the introduction to this series, and parts two and three will follow shortly. I ask in these essays: Who is on the other side of a conversation with an AI chatbot? What is this chatbot persona that is ready to happily write back at any time of day? How is this powerful illusion created, and why should we care?
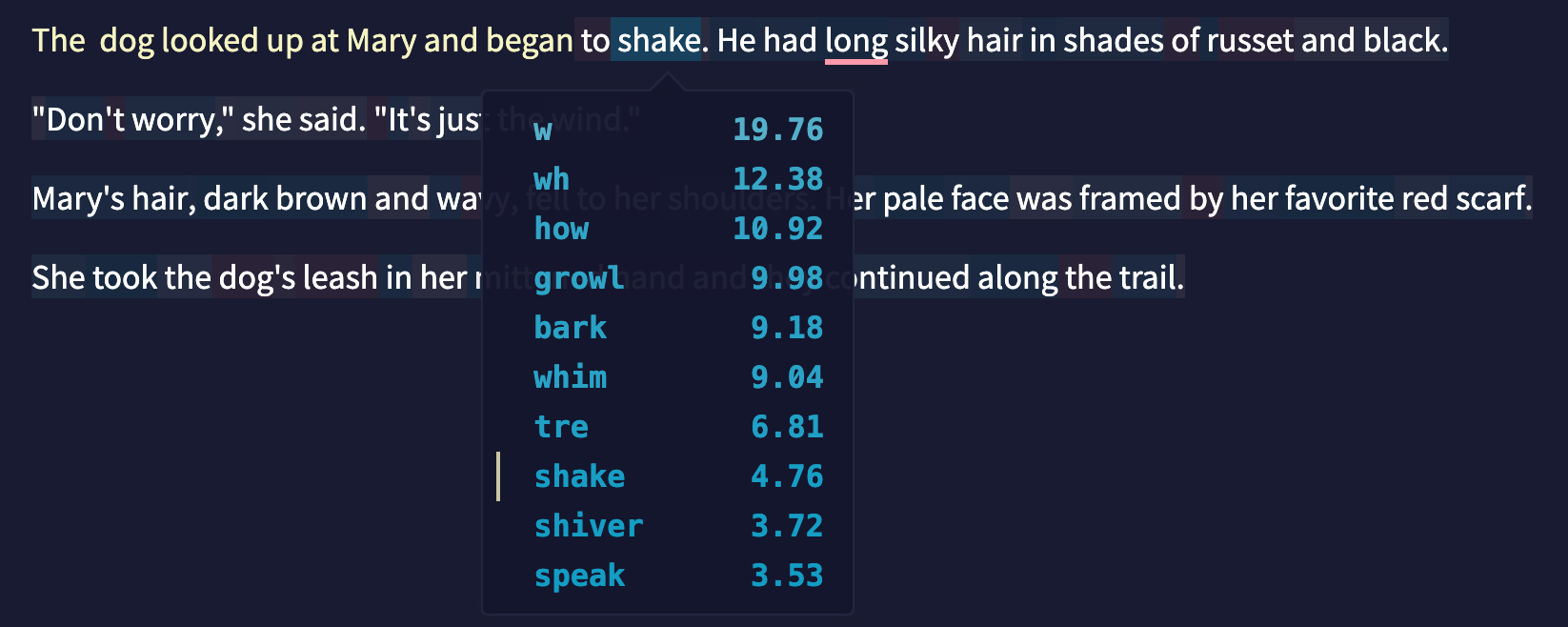
This is an image of NovelAI’s editing panel. NovelAI is an AI writing platform designed specifically for creative fiction writing. The platform features a minimalist sandbox environment for text generation without conversational pretenses; the editing panel operates as an open-ended text playground of sorts, allowing users to focus solely on text generation. This means that users have direct access to the underlying language model’s text completion operations. In this example, I had entered the first few words (marked in yellow), and the language model continued the text. Clicking on output words shows probability scores (I checked “shake”), revealing the mathematical process behind the text creation.
It’s worth spending some time thinking about the implications of this AI writing tool for a writer’s writing process, but for my purposes here, NovelAI’s sandbox approach is particularly valuable for understanding how large language models (LLMs) actually work under the hood. By removing the illusion of conversation and fictional personas, what remains are the raw text completion mechanics that power all AI language systems.
In this series, I examine three interconnected components of AI chatbots:
The generative AI technology (language models themselves)
The specific user interfaces of AI chatbots
The fictitious chatbot character that completes the illusion of interacting with an intelligent entity
The introduction to this series provided the context and presented a brief explanation of the underlying technology behind AI chatbots. I covered how language models work and suggested some preliminary takeaways about their social and cultural impacts.
In this post, I want to present a hands-on exploration of how language models generate text by getting a sense of a raw model’s functionality *before* it becomes a chatbot through a specific user interface.
Such an examination of the technology itself helps foster a deeper understanding that will equip us with the expertise to determine whether to use an AI chatbot for a particular task and how to do so responsibly. Raw language models feel very different from the typical AI chatbot after it receives a human-like interactive interface. The language model itself is like an automatic word machine that repeatedly calculates and spits out a likely next word.
Using a raw GPT
An LLM is a GPT system: a generative pre-trained transformer that computes statistical relationships of language patterns to provide their best guess of a likely next word based on the input text (prompt) you give it.
The major commercial AI platforms do not provide access to their raw language models because their designers have added interfaces and chatbot personas (through hidden instructions that run in the background when the user inputs a prompt), which we will discuss in Parts 2 and 3 of this series.1
The subscription platform NovelAI is marketed as "AI-assisted authorship," fine-tuned for generating anime images and crafting stories. The free trial provides 50 prompts, which is sufficient for this introductory exercise, allowing us to get a sense of how language models generate text. NovelAI offers users a range of controls and options that enable various modifications and fine-tuning of the output. Though the learning curve can be rather steep, for this exploration, we will use only a few settings in NovelAI to get a sense of the language operations of a GPT system.
An important caveat is in order: NovelAI was launched in 2021, closely tied to the dissatisfaction of many users and fans of AI Dungeon, a first-of-its-kind text adventure game that had players create random storylines with an integrated language model.2 NovelAI deliberately avoids safety filtering and content moderation that most AI companies implement (including AI Dungeon). It will generate unfiltered output, including potentially biased, offensive, or degrading language. As I explain later in this post, several opt-in user controls exist, but without specifying such restrictions, be aware that unfiltered words could be generated because that’s how language models work: they detect patterns in the language data they have been fed and mimic that data (bias and all) in their outputs.
Word explorations in NovelAI
The top of NovelAI’s landing page looks like this:
We will select "Create Stories," and we can create an account or use the application without it.
The screen/interface looks like this:

The top arrow in the screenshot indicates that a user has 50 out of 50 free text generations left, and we also see that "8192 tokens" are available for AI context, which is the length of input we are allowed to provide. The second arrow in the bottom left corner allows a user to enter the writing interface. We will click here and select "Storyteller" mode on the next page.
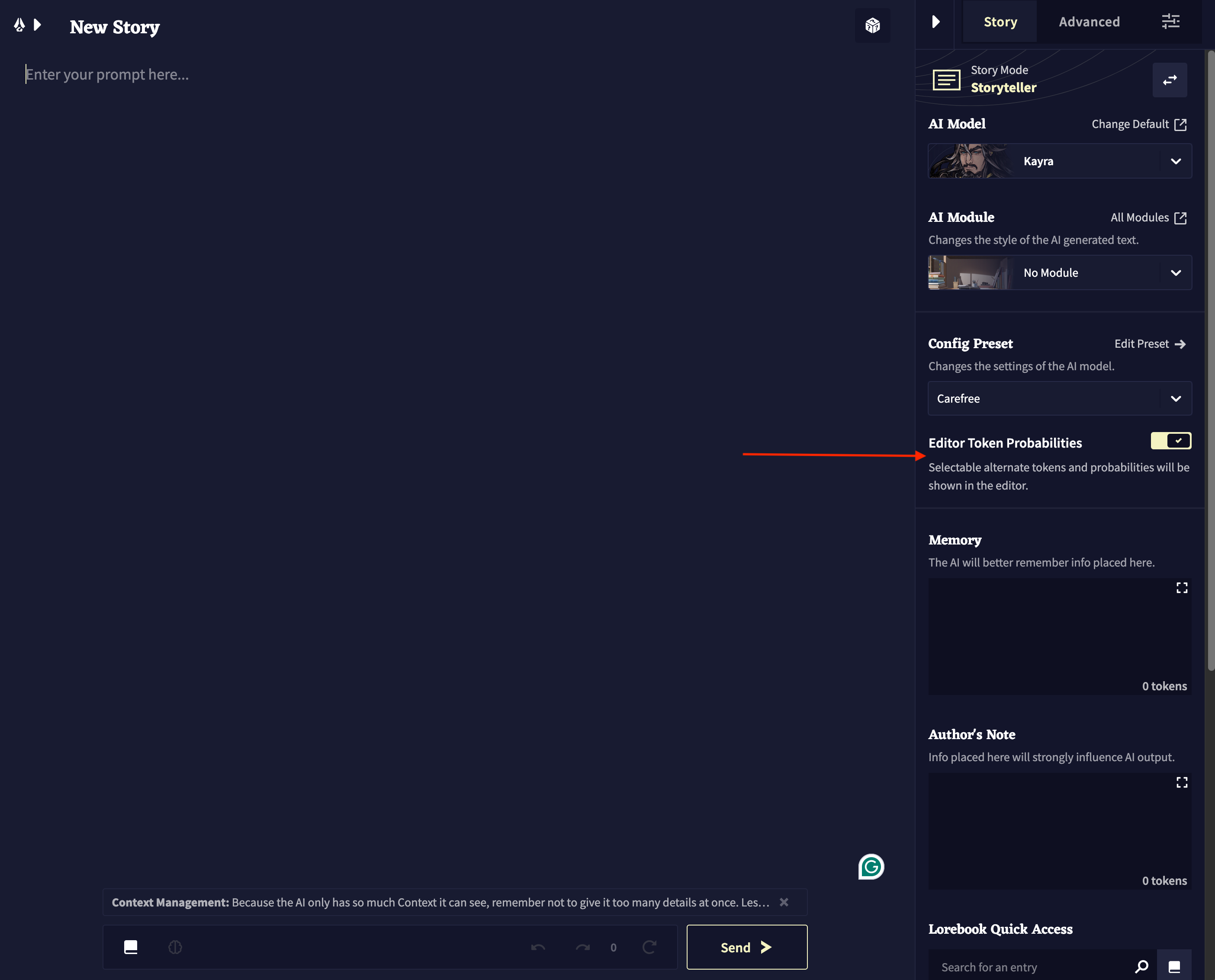
The writing interface presents a blank canvas consisting of a writing/editing panel into which the user enters text and the model generates its output. By hitting the "Send" button at the bottom, a user sends a text sequence to the language model for completion. There is no visual separation between a user's writing and the bot's output--all writing is displayed as continuous text in this editing panel. On the right-hand side, let's only activate the option "Editor Token Probabilities" (we will change other options later).
It's really informative to play around with this tool, which provides direct access to language models. I am starting by entering one word: "the." We thus let the GPT begin its statistical calculations based on just one word.
I got this output (if you’re trying this yourself, the output will be different):

Let's think about this result. What's happening here? In short, the model processes the word/token "the" and begins the statistical completion process one word at a time. When we only give it one word, the context into which this word fits is undefined and open-ended. The model has free rein to randomly pick the next word from nearly infinite semantic probabilities in the English language.
First, it processes the input and outputs ONE new word, randomly picking one of the many words that its training data indicates could follow "The," ending up with "The young" in my case; then, it takes the new word string ("The young") and plugs into the model to get the NEXT word ("The young woman"). The next computation takes “the young woman” and adds to it one new word, to yield “The young woman,” (note that a comma counts as a token), followed by “The young woman, with.”
This process is repeated over and over for a while until a coherent-looking string of words is generated. That is to say, each word of the output is based on mathematical calculations of the string of words that precede it. All of this is based on word probabilities in the language model's vast training data. In other words, each generated sentence completion represents a model's guessing game about what sets of words are similar and what words are likely to appear in specific contexts or regions of text space.
If you look closely, the first word, "the," is yellow, and the model's output is in white font, which indicates which words I wrote versus the model's output.
Clicking on any of the output words opens up a list of token probabilities and shows which word the model selected in its probability guessing game:


In my case, it landed on "young," which shows a 6.44 percent probability of following the word “the,” followed by the word "woman," which shows a 29.87 percent likelihood of following the phrase "the young." We see here that the model does not pick the highest probability, but that its guesses include a measure of "creativity." We'll return to this variable momentarily.
What's really instructive in NovelAI is that we can edit this output at any time to prompt the language model to calculate a new one-word-at-a-time word string. For example, I deleted everything after "sitting on a" and entered "river bank." Now, the model needs to complete this word string, “The young woman, with her dark-skinned, olive-green eyes and black, slightly wavy hair, was sitting on a river bank,” which forms the semantic context for the next word/token:



As we can see in the third screenshot, for the next word, it picks the second option, a period (31.35 percent probability), among the token probabilities that could follow the word string I entered. From there, it continues this process, generating one new word at a time by considering the entire preceding string of words as its context to compute the next likely word.
Of course, I can edit the text anywhere I want by adding new words, deleting others, and prompting the model to continue the text at any time. Playing around with these minimalist prompts shows the guessing game inherent in the language model. A good analogy would be a Google Doc, in which the user AND the GPT generate parts of the document. I can add text to the returned output, and the model will provide additional text. However, this text generation process is not a conversation; there is no one on the other side. In the GPT's editing panel, the model calculates the most probable word continuations and then chooses among those. Both my text and the GPT’s output exist in this editing panel as signs (signifiers, really), strings of linguistic units.3 As far as the model is concerned, it automatically churns out signifiers after it computes the linguistic system’s vector distributions. The GPT’s word generation is entirely a product of statistical calculations.
We can experiment with this word generation game in NovelAI by adjusting various statistical parameters of the model's calculations. Let's edit a few of these by working with the options panel on the right-hand side of the interface.
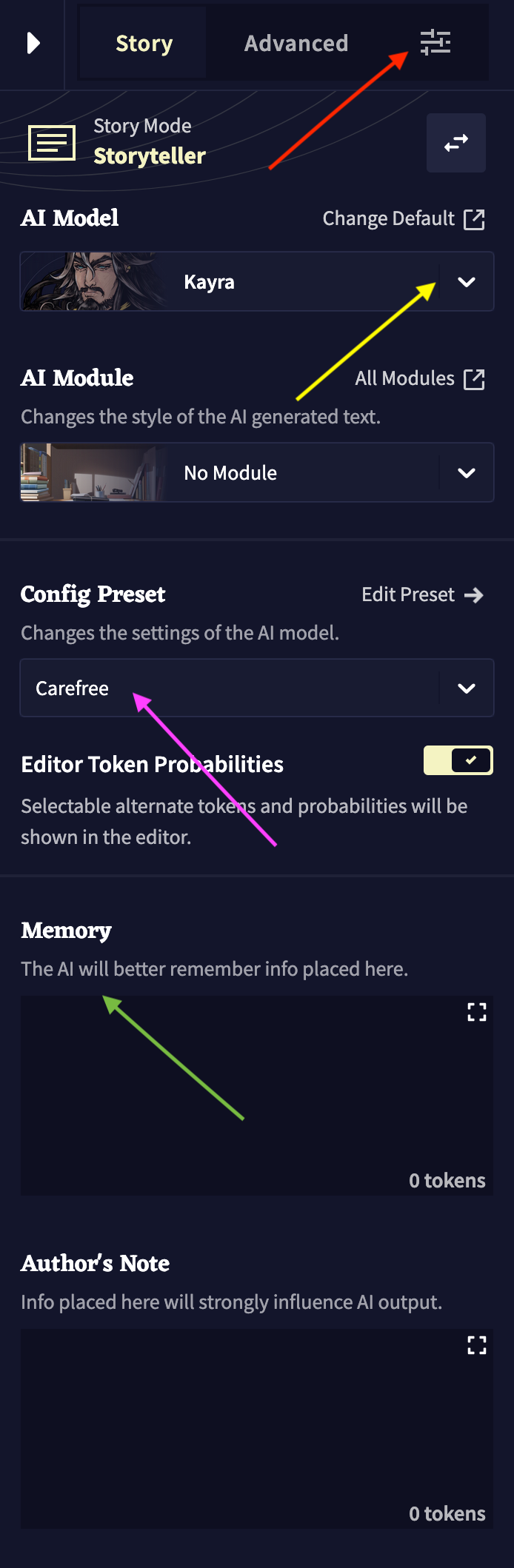
Yellow arrow: We can review different generations of language models used by NovelAI, with some details about their differences. The current model Clio was trained from scratch by NovelAI engineers using custom training sets.
Pink arrow: The five presets offer different types of parameters in an easy-to-select predesigned format.
Red arrow: This option menu lets users select many options as part of the "Advanced" setting. We can adjust the model's randomness distribution, output length, and repetition penalty (the frequency with which we want the model to repeat the same words). Other options further down the Advanced Options column address technical parameters, such as sampling options, phrase repetition penalty, banned tokens (filtering out semantic contexts we don’t want the model to generate), etc. NovelAI's documentation provides details for learning more about all these options.
For now, let's experiment with the "temperature" setting, which controls the model's randomness. Setting the temperature to 0.25, for example, makes the model choose the most statistically likely next word, as in this screenshot (I entered the word string, "The untold story"):
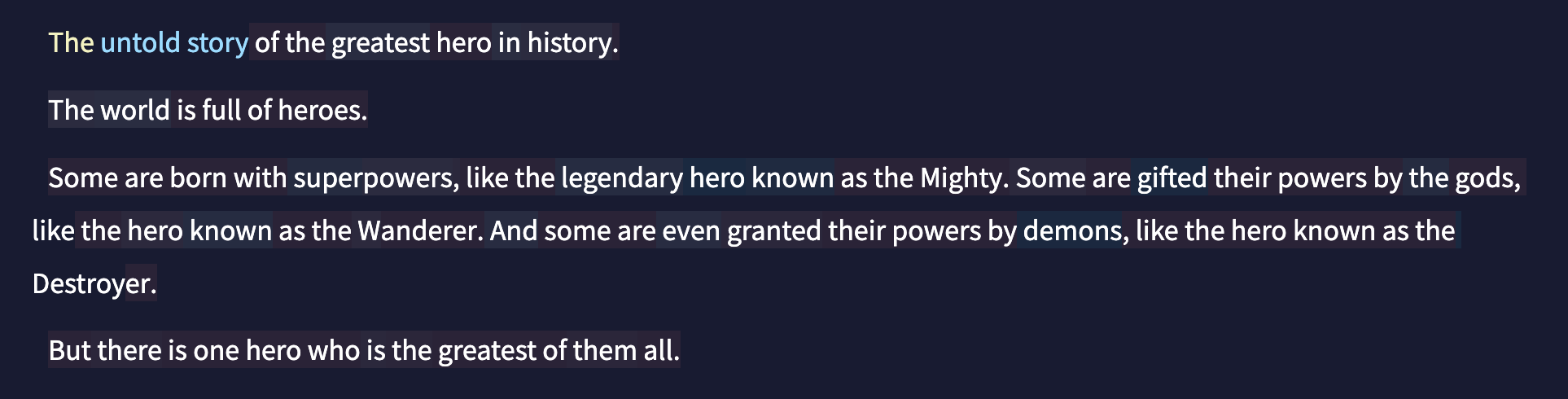
The generated text is predictable: this is a story of great heroes, history, superpowers, legendary gods, demons, destroyers…. Kinda sounds like your popular, blockbuster action fantasy movie at the corner cinema playing right now.
Changing the temperature to 2.4 directs the model to pick from less probable options, which feels more improvisational:

Not only does the theme of the generated story shift away from predictable characters, connecting more disparate semantic text spaces such as boy, death, notebook, and school, but the form changes as well, becoming more fluid and experimental.
Writing a non-sensical string of words (blue color below) primes the model to output similarly non-sensical new words before it returns to generating grammatically congruent word strings based on its training data:

This exploration demonstrates that a GPT system operates at the level of words/tokens to produce new words in a probabilistic game of calculations. NovelAI's minimalistic interface allows us to get a sense of this computational guessing game as it reveals this mechanism. The model doesn't "know" what it was going to talk about until the very moment that it generates the first new word, and then the next word, and the next. Overall, then, NovelAI's access to a raw language model allows users to see the mindless pattern-matching nature of this technology. Crucially, then, these linguistic guesses are entirely “freed” from meaning, decorum, or valuation. This is linguistic play, for better or for worse.
Dictating the conversation rules
But how do we get from this raw language model to the commercially available AI chatbot systems that have been inundating our digital devices? Well, we can experiment a bit more with additional options in NovelAI. We can create "memory prompts” that the model is instructed to add to the word strings we provide for completion. These memory prompts provide context, scenarios, or additional parameters a user wants a model to use when it completes text. For instance, we can set up a story in a way that makes the model maintain a "chat style" narrative between two characters, while keeping the role of one of the characters strictly under our control.
To do this, I follow NovelAI’s chat format instructions, programming a set of rules in the Memory box (red arrow below) and changing the phrasing bias under "Advanced" options. After I provide a sample conversation (yellow arrow below), the model will complete its next-word prediction based on the memory prompt AND the sample dialogue I provided. Those two sets of word strings (prompts) set it on a path to select words that match the specific text space it has been given. Its word completion takes the form of a chat until it reaches the maximum number of tokens I specified.
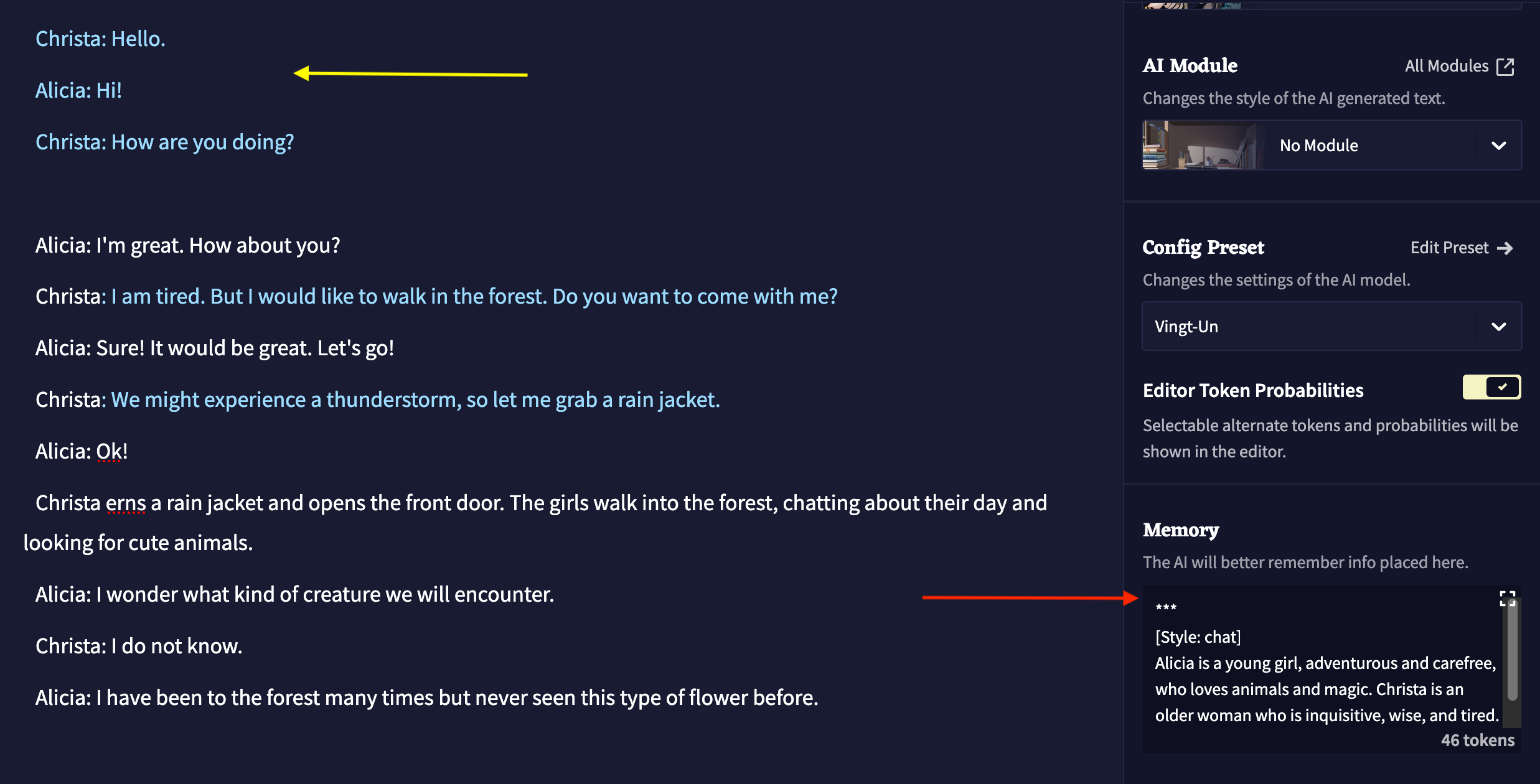
What we see here is that the additional programming now tells the model to format its output differently. There is still no bot called Alicia for me to talk to. The permanent memory prompt has added the words "Alicia" and "Christa" into the output. That is to say, "Alicia" and "Christa" are fictional lines (or characters) added to the output. As soon as I add more text, and the model uses it to compute the next word and the next word after that, the overall document ends up looking like something that resembles a conversation transcript. However, the two participants are entirely made up. The model still wants to complete the word strings I have entered, including character parts, if the prompt tells it to use those words. The language model does not care about those names, nor does it have an internal sense of itself as "Alicia" or "Christa."
Now, even more programming can instruct the model to supply only the lines for "Alicia," and to stop after it generates the word "Christa" (this is done by changing the parameters under “Stop Sequences” in the Advanced panel). In this way, the model’s output will stop with the line “Christa:” I can then add more text after my "name." An illusion begins to emerge. It feels as if a conversation is happening right in front of my own eyes, wherein I occupy the character of myself, and the language model becomes Alicia. This illusion is so powerful (and we're so conditioned to conversation modalities from other interactions on social media and communication devices) that it's easy to forget we're actually seeing automatic text dressed up as a fictional entity called "Alicia."
Finally, as one final demonstration, here's the "script" NovelAI generated after I changed the names of the characters and provided the following instruction to its system memory: "[Style: chat] The Universe has a playful character, sometimes satirical and funny, but always thoughtful and wise. The wind is young, adventurous, and naive." My text is blue, and the synthetic text is white.

This is wild! Clearly, NovelAI's GPT model is fabricating all this text, without any sense of subjectivity or purpose. It's modeling the distribution of words based on probability parameters and "script" instructions the user has provided. It was told to mimic a conversation--in the sense that it outputs word strings it has calculated from its vast training data in the form of a “conversation."
One final observation and clarification are in order. The Advanced tab provides at the very top a “Context” option. Clicking on “Last Context” gives us this information about the model’s operations (this is one long screen represented in two screenshots):

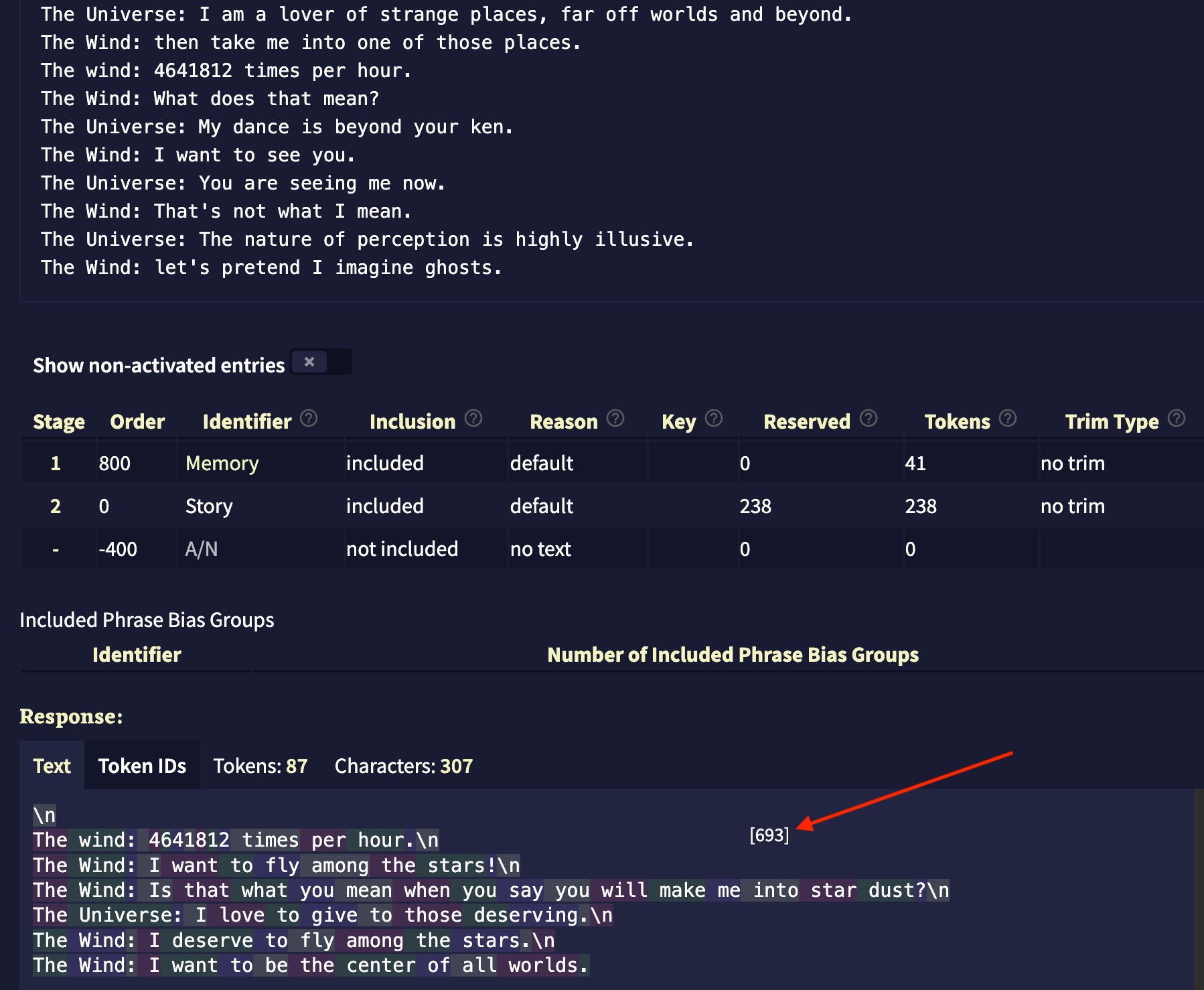
This context information shows exactly which tokens the model uses to complete its word guessing. The very top tells us that it has been given 279 tokens (out of 8096 possible maximum tokens—which is a lot!); these tokens are made up of 41 tokens of memory prompt (marked in yellow font in the text box), followed by 238 tokens of the previous text. The model uses all these tokens as its prompt to generate the next word. The “response” section at the bottom shows the new tokens it has generated. For each new token, the model will have computed the entire string of words, every single time, to generate one word at a time. Hovering over any of the tokens reveals each token’s numerical ID (red arrow), which the model uses for its statistical calculations in the next-word-prediction process.
We can understand how prompts function like contexts that guide a model’s output. They provide information to shift the model’s learned probability distributions toward more relevant completions. Longer contexts lead to more focused and controlled outputs, while short contexts provide less information to condition the probability calculations on, resulting in a sometimes scattered and random feel. Changing even one word in the context can significantly alter the output because the model’s vast web of learned associations gets nudged onto an entirely different trajectory. As we noted earlier, temperature settings act like a creativity dial on this process, affecting how deterministically the model selects from probable next tokens. And finally, a conversation format is the result of prompts that turn mechanical text generation into outputs that follow specific linguistic patterns, simulating conversation dynamics.
At this point, it is essential to note that all the text explorations we've conducted with NovelAI have been in a fictional context (a dreamscape, really). But the key point is that the GPT technology shares a similar underlying architecture and generates text probabilistically in all commercial, large language models (ChatGPT, Claude, Gemini, Copilot, etc.) that are marketed as tools for non-fictional text tasks. While they differ in their training corpora and fine-tuning approaches, they do not retrieve stored facts but generate synthetic text. From the machine's perspective, its calculations work in the same probabilistic manner as NovelAI's text computations do. In other words, a language model does not try to be "correct;" it remains a sophisticated autocomplete system based on probability calculations from its training corpus. All these models, regardless of their marketing or advertised use cases, are fundamentally probabilistic text generators. They don’t have factual knowledge in any traditional sense; they generate plausible-sounding text based on statistical language patterns.
In this context, the term "hallucination" refers to when a model produces an output that appears confident and plausible, but is factually incorrect or entirely fabricated. But as we can see from our experimentations here, everything a language model creates is "fabricated" in the same way. Text output is the result of a model's computational pattern calculations learned from its training data and the user's input text. A model cannot assess accuracy or report on the real world. It mimics the linguistic patterns it has calculated from its training data. Thus, the term "hallucination" is misleading as it suggests that a model made a "mistake" and actually wants to report on the world, but suffers some breakdown in that reporting. It is important to recognize here that such errors are not occasional lapses but direct consequences of their computational architecture and predictive logic. Even when language models produce ostensibly "true" sentences, they do so without recourse to intentionality or a sense of veracity. Its output may or may not correspond to reality, though most of the time, it seems reliable because the gigantic training corpus these models use produces high-plausibility guesses.
The next post in this series will discuss user interfaces and how they steer a user’s experience into a conversational format, creating the illusion of an ongoing relationship and shared context.
Notes:
For this series, I am adapting Colin Fraser’s approach to understanding how AI chatbots work. In his Feb. 2023 essay, Fraser used OpenAI’s Playground to show a language model’s mechanism at work. As I’m writing this post in June of 2025, OpenAI has discontinued the sandbox capability in Playground unless you pay for full API access to their model. Consequently, I’ll be using a different language model sandbox, NovelAI.
AI Dungeon was started in 2019 by a student at Brigham Young University in Provo, Utah, which, incidentally, is a couple of miles away from the large public college where I teach. I recall my younger son mentioning this new adventure storywriting game that utilized a language model for text generation of characters and storylines. My son was one of the early players who subsequently migrated to NovelAI. The first version of AI Dungeon used OpenAI’s GPT-2 model, which was initially withheld from public release due to concerns about potential misuse. Still, this model was already incredibly promising in terms of its large size and capability to generate coherent text over longer passages. To make a long story short, through a new monitoring system, OpenAI discovered that some AI Dungeon players got the model to generate problematic sexual content, and it immediately asked the game developers to install an algorithmic moderation and censorship system that proved to be unreliable and frustrated many players. The resulting backlash from the player community created the conditions for alternative platforms like NovelAI that committed to unfiltered content generation. What seems noteworthy here is that platforms like AI Dungeon and NovelAI showcase a potentially important use case for language models in enabling creative and interactive text generation in an exploratory, dynamic, and low-stakes writing environment.
So, this point about words existing only as signifiers in the program’s editing panel is quite remarkable. It definitely resonates with Roland Barthes’s work on semiotics. In the editing panel, the signifier exists without ownership or valuation. It exists as data for the machine AND the human user. Barthes explains, “A language and a style are data prior to all problematics of language” (p. 13). Seth Perlow says we are “entangled with textual machines” as “both generate complex but predictable language based on texts we have previously read” (p. 552). Perlow challenges us to confront this predicament because big tech is leveraging its own reactionary ownership of training corpora and language technologies.